
撰写于 浏览:487 次 分类: 决策树
信息增益比(GainRatio)的定义:在选择决策树中某个结点上的分支属性时,假设该结点上的数据集为DataSet,其中包含Feature个描述属性,样本总数为len(DataSet)或者DataSet.shape[0],设描述属性feature(不同于Feature,Feature是属性的个数,取值为DataSet.shape[1],featur[...]

撰写于 浏览:430 次 分类: 决策树
ID3 算法的数学原理ID3树算法中是依赖信息增益G(D,A)=H(D)-H(D|A)来选择最佳的分类属性。具体的实例参照:第四节:信息增益的计算。链接为:http://www.treekit.cn/archives/11.htmlID3算法存在一定的缺陷假设每个记录有一个属性“ID”,若按照ID来进行分割的话,由于ID是唯一的,因此在这一个属性上[...]
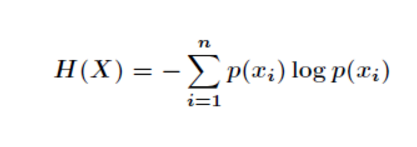
撰写于 浏览:846 次 分类: 决策树
1、信息熵与条件熵信息熵是考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。公式如下: 而条件熵的定义是:在给定条件X下,Y的条件概率分布的熵对X的数学期望,其公式推导如下所示:2、条件熵应用场景假如我们有下面数据:设随机变量Y={嫁,不嫁},我们可以统计出:嫁的个数为6/12 = 1/2不嫁的个数为6/12 = 1/2那么Y的[...]
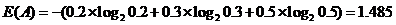
撰写于 浏览:521 次 分类: 决策树
在划分数据集之前和之后信息发生的变化称为信息增益。举一个数据分析的例子:根据游戏活跃用户量进行分类,分为高活跃、中活跃、低活跃三大类。游戏A按照这个方式划分,用户比例分别为20%,30%,50%。游戏B也按照这种方式划分,用户比例分别为5%,5%,90%。那么游戏A对于这种划分方式的熵为:同理,游戏B对于这种划分方式的熵为:游戏A的熵比游戏B的熵大[...]

撰写于 浏览:425 次 分类: 决策树
熵的概念起源于热力学,是一种分子混乱程度的度量:如果分子保持静止和良序,则熵接近零。后来这个概念被传播到各个领域。在机器学习中,它也经常被当做不纯度的测量方式:如果数据集中仅包含一个类别的实例,则熵为零。机器学习的本质是信息论。在信息论中,首先我们引入了信息熵的概念。认为一切信息都是一个概率分布。所谓信息熵,就是这段信息的不确定性,即是信息量。对于[...]