撰写于 浏览:1327 次 分类: 决策树
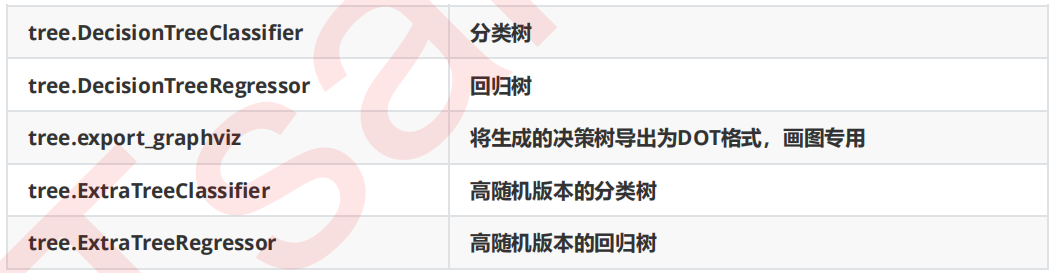
1、scikit-learn中的决策树决策树是一个非参数的监督式学习方法,主要用于分类和回归。决策树算法的目标是通过推断数据特征,学习决策规则从而创建一个预测目标变量的模型。scikit-learn中决策树的类都在sklearn.tree这个模块之下,这个模块总共包含五个类:2、scikit-learn的安装scikit-learn是一个用于机器学[...]


撰写于 浏览:1144 次 分类: 决策树
决策树的优点是简单,逻辑清晰,具备可解释性,但是也有一个很大的缺点:非常容易过拟合,解决过拟合的方法主要是有剪枝、随机森林等。从随机森林的名字上就能猜出,这种方法无非是信奉”人多力量大“这句话,把诸多决策树集成在一起,进而形成一个更强大的树树树模型。随机森林是一个Bagging方法,Bagging是一种有放回抽样方法:取出一个样本加入训练集,然后再[...]
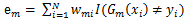
撰写于 浏览:1070 次 分类: 决策树
Boosting 是一类算法的总称,这类算法的特点是通过训练若干弱分类器,然后将弱分类器组合成强分类器进行分类。为什么要这样做呢?因为弱分类器训练起来很容易,将弱分类器集成起来,往往可以得到很好的效果。俗话说,"三个臭皮匠,顶个诸葛亮",就是这个道理。这类 Boosting 算法的特点是各个弱分类器之间是串行训练的,当前弱分类器的训练依赖于上一轮弱[...]
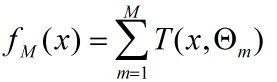
撰写于 浏览:1351 次 分类: 决策树
提升树模型采用加法模型(基函数的线性组合)与前向分步算法,同时基函数采用决策树算法(对待分类问题采用二叉分类树,对于回归问题采用二叉回归树)。提升树模型可以看作是决策树的加法模型: 其中T()表示决策树,M为树的个数, Θ表示决策树的参数。提升树算法采用前向分部算法,首先确定f0(x) = 0,第m步的模型是:对决策树的参数Θ的确定采用经验风险最小[...]